|
|
|
|
|
通過大眾需求....
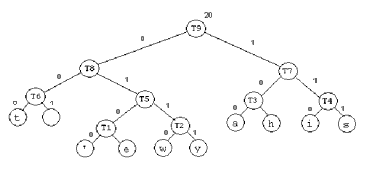
如何壓縮功? 主要有兩種類型的壓縮方法 - 無損壓縮和有損壓縮。 哈夫曼樹壓縮是一種方法,通過它可以重建原始數據完全從壓縮數據,因此它屬於無損壓縮家庭。 如何壓縮 Huffman樹的工作? 哈夫曼樹達到壓縮通過使用可變長度代碼。 為了成全畫像,讓我們說,我們要壓縮的文本文件,其中包含的文字: 在一個普通的文本文件,將每個字符佔用 1個字節(8位)。 由於有16個字符(計空格和標點符號),它通常會佔用 16個字節。 但是, 為什麼我們需要分配給每個字符1字節擺在首位? 有256個可能的字符按照ASCII碼 ,這使我們使用8位來表示每個字符。 在任何文本文件,但是, 我們並不一定要使用的所有256個字符 。 此外, 一些更常用的字符 ,例如,在英語文本,字符'e'的可能出現的頻率比字符'z'的。 為了達到壓縮的,我們可以用更短的位串表示一個更頻繁發生的特點,和較長的位串來表示不經常發生的字符。 我們沒有代表所有256個字符(因此,我們或許可以用遠低於每8位字符),除非他們都出現在文件中,我們試圖壓縮。 回到我的例子,我們可以,比如使用一個比特來表示'一'。 只憑這一點,我們可以用少於 14個字節來表示的句子。 這就引出一個問題,但是。 如果我們使用下面的代碼(分配從 0到7,'0'是最短的字符串和'111'是最長的字符串): 男:11 “夫人,I'mAdam。” 你可以看到這個問題。 將會有不止一種方法來解釋代碼,如果我們分開在不同地方的代碼(到碼字)。 這將是非常低效的,如果我們用一些特殊字符分隔兩個碼字 - 因為我們正在嘗試使用不到1個字節表示一個字符,特殊字符會佔用 1個字節了! 因此,我們只需要使用前綴碼 。 如果我們確保每一個碼字,碼字的不存在也是一個碼字的前綴,那麼我們就可以單獨一個代碼為唯一碼字。 例如,如果為0,110和11個碼字,然後我們說前綴碼不使用,因為11是前綴110。 當我們試圖解碼 '1100',我們可以把它分開 110 | 0,或11 | 0 | 0。 不存在這個問題在修復長編碼(如ASCII碼),因為我們知道,每一個代碼正好是8位長。 我們到底如何,找到前綴碼 /字碼每個字符,同時保持他們盡可能短? 我們建立了一個二元樹: 1。 初始化:把所有的節點在一個開放列表,保持在任何時間排序(例如,abcde的)。 2。 打開列表重複,直到只有一個節點左: 一個樹是使用上面的步驟說明。 當一樹建成,我們對每個字符分配碼字,如下面的例子(這是不同的例子,我們一直在使用):
電話:000 我們注意到,代碼生成的前綴碼,因為字符只能出現在葉級樹。 當我們使用字碼生成編碼的文件,因為我們達到壓縮的碼字,一般短於 8位。
|
©版權所有2002-2011。 保留所有權利。
Software on this web site is provided "as is". Use at your own risk.